自从去年GDC释出了一些消息以来,D3D12 SDK终于在上个月底随着VS2015RC公开了。除了API的更新,D3D12还包含了一个称为11on12的库,让移植前所未有的快捷。目前KlayGE的D3D12插件正在开发中,本系列文章将会把一些方法和经验总结出来。简单起见,后续的代码省略了错误检查等细节。同时,阅读本系列的前提是对D3D11有基本的了解。
D3D移植的过去
纵观D3D的历史,几乎每个版本都是从新开发,和旧版本没有接口上的继承关系。也就是说,和一般COM组件的概念不同,不能从新版本的接口QueryInterface出老版本的接口。结果就是,每次需要移植到新的D3D版本,都会需要拷贝代码、修改代码,甚至重写。在整个渲染部分都换到新API之前,系统完全无法工作,我们也不会看到任何渲染结果。
拿我使用过的D3D版本为例。最早我用的D3D 5.2,后来升级到D3D 7之后,花几个月从零开始重写整个3D渲染,DDraw部分倒是没太大变化。升级到8之后,接口全变,也不再需要DDraw。所以我再次花了几个月重写3D渲染。从8升级到9,接口很接近,但仍然需要用查找替换的方式,把8替换成9的API,并修改部分代码,花了大概几天时间。9升级到10再次经历了一次完全重写,前后40天左右。前几年从10到11,如果不考虑11新增的硬件功能,两者接口非常接近,绝大部分代码可以通过查找替换来升级(除了建立DSV的时候多了个Flags参数之外)。
这次从11到12,API再次巨变。按照以往的经验,重写是不可避免的。但如果移植如此艰难,对开发者来说不是什么好事。于是在D3D历史上第一次,官方提供了一个用新API实现老API的高层封装。通过这层接口,我们可以从D3D12的设备上建立出一个特殊的D3D11设备。这个设备可以完全当成一个传统的ID3D11Device来使用,但因为其本质是D3D12,能和ID3D12Device有一定的交互能力。于是乎,我们可以让程序处于11和12之间的一个状态,而不是非11即12。移植变得前所未有的简单。
(用新API实现老API这招,其实在别的地方屡见不鲜了。KlayGE的渲染层接口就很接近D3D11,但底层曾经有D3D9插件。这次D3D12从API设计的角度来说,比11底层,所以用它来实现个11的接口也是理所当然的。)
建立设备
KlayGE的D3D12插件,代码是从D3D11插件拷贝过去的,并通过查找替换把类名中的11换成12,但实现上仍然是用ID3D11那些。以此为基础,我们需要一点一点往前突破,把这个插件移植到D3D12。
第一步一定要做的就是建立设备。看了一眼接口,
HRESULT D3D12CreateDevice(IUnknown* pAdapter,
D3D_FEATURE_LEVEL MinimumFeatureLevel,
REFIID riid,
void** ppDevice);
对比D3D11的建立接口
HRESULT D3D11CreateDevice(IDXGIAdapter* pAdapter,
D3D_DRIVER_TYPE DriverType,
HMODULE Software, UINT Flags,
const D3D_FEATURE_LEVEL* pFeatureLevels,
UINT FeatureLevels, UINT SDKVersion,
ID3D11Device** ppDevice, D3D_FEATURE_LEVEL* pFeatureLevel,
ID3D11DeviceContext** ppImmediateContext);
D3D12CreateDevice的参数D3D11CreateDevice很像。12里只需要给最低的feature level,比11的feature level列表更简洁。12需要提供GUID也使得未来不需要提供新的API就能进一步扩展。至于建立出来的设备feature level,事后可以单独Get,其实不必在这里提供。但同时也会发现,几个参数没了。第一个是D3D_DRIVER_TYPE DriverType,以前用这个可以指定软件还是硬件还是WARP还是REF。现在这个参数没了,如何指定?第二个是HMODULE Software,可以提供一个软件渲染器的模块,这个非常少用。UINT Flags可以指定是否使用debug layer,这个没了如何开启debug?UINT SDKVersion是为了历史兼容,没啥用。ID3D11DeviceContext** ppImmediateContext的概念在D3D12里改了,需要在后面单独建立command queue,所以也不需要了。
好了,那么问题就集中在两个参数。一是DriverType,而是Flags。
在Win8上,WARP已经从一个用户态dll移到了内核驱动,称为Microsoft Basic Render Driver。它取代了VGA Adapter,在没有显卡驱动的时候提供基础的显示功能。在系统看来,这是一个永远存在的“显卡”。只要系统启动,就一定可以在上面建立设备。这么一来,就其实不需要通过一个参数来制定WARP设备了,而就用第一个参数pAdapter,把WARP的adapter提供进来就行了。在新的IDXGIFactory4里,专门提供了一个函数EnumWarpAdapter,用来返回系统的WARP adapter。这就解决了DriverType问题。
至于debug layer,现在其实也独立成一个接口,可以单独启用。
ID3D12Debug* debug_ctrl;
D3D12GetDebugInterface(IID_ID3D12Debug,
reinterpret_cast<void**>(&debug_ctrl));
debug_ctrl->EnableDebugLayer();
debug_ctrl->Release();
最后,D3D12设备的最低要求是D3D11的硬件。所以MinimumFeatureLevel如果低于11_0,就一定会失败。我的笔记本是Intel HD 3000,只有10.1,所以暂时只能用WARP跑12。
凑齐这些之后,我们就能建立出想要的D3D12设备了。
建立command queue
D3D11的时候,device context会随着设备建立出来。在它上面调用渲染指令就能画出东西。到了12,这个概念由command queue完成。在设备建立之后,可以用
D3D12_COMMAND_QUEUE_DESC queue_desc;
queue_desc.Type = D3D12_COMMAND_LIST_TYPE_DIRECT;
queue_desc.Priority = 0;
queue_desc.Flags = D3D12_COMMAND_QUEUE_FLAG_NONE;
queue_desc.NodeMask = 0;
ID3D12CommandQueue* cmd_queue;
d3d_12_device->CreateCommandQueue(&queue_desc,
IID_ID3D12CommandQueue, reinterpret_cast<void**>(&cmd_queue));
得到command queue之后,D3D12的初始化就完成了。
11on12显身手
下一步,我们将通过11on12,在12的设备上建立出一个11的设备。需要注意的是,这个函数位于d3d11.dll,而不是d3d12.dll。
HRESULT D3D11On12CreateDevice(IUnknown* pDevice, UINT Flags,
const D3D_FEATURE_LEVEL* pFeatureLevels, UINT FeatureLevels,
IUnknown** ppCommandQueues, UINT NumQueues, UINT NodeMask,
ID3D11Device** ppDevice, ID3D11DeviceContext** ppImmediateContext,
D3D_FEATURE_LEVEL* pChosenFeatureLevel);
这个函数的大部分参数和D3D11CreateDevice一样。区别在于需要传入D3D12的device和command queue。至于NodeMask,我现在用的0,没出什么问题。这里的feature level,可以低于11_0。建立出的D3D11设备可以进一步获取到一个D3D11on12的设备。
ID3D11On12Device* d3d_11on12_dev;
d3d_11_device->QueryInterface(
IID_ID3D11On12Device, reinterpret_cast<void**>(&d3d_11on12_dev));
那么,是不是这么建立出来的ID3D11Device放到插件里就行了,其他D3D11的代码都能神奇地复用了呢?我一开始也是这么认为的。但一运行,crash在获取back buffer的时候。
ID3D11Texture2D* back_buffer;
swap_chain_->GetBuffer(0,
IID_ID3D11Texture2D, reinterpret_cast<void**>(&back_buffer));
11on12是D3D的,而swap chain来自于dxgi,所以没那么简单就能让11的代码全都工作起来。这里GetBuffer实际上获得的是ID3D12Resource的对象,也就是他直接访问到了12的back buffer。我们需要做的是,在12的back buffer上建立render target view等。在此之前,首先我们需要一个descriptor heap,用来存放render target view。
D3D12_DESCRIPTOR_HEAP_DESC desc_heap = {};
desc_heap.NumDescriptors = NUM_BACK_BUFFERS;
desc_heap.Type = D3D12_DESCRIPTOR_HEAP_TYPE_RTV;
desc_heap.Flags = D3D12_DESCRIPTOR_HEAP_FLAG_NONE;
ID3D12DescriptorHeap* descriptor_heap;
d3d_12_device->CreateDescriptorHeap(&desc_heap,
IID_ID3D12DescriptorHeap, reinterpret_cast<void**>(&descriptor_heap));
rtv_desc_size_ = 0;
有了descriptor heap,我们就能开始建立back buffer的render target view了。和以往不同的是,12的swap chain可以访问到每一张back buffer,而不是全都封装成由系统管理的一张back buffer。开发者也需要负责对每一张back buffer建立一个render target view。
rtv_desc_size_
= d3d_12_device->GetDescriptorHandleIncrementSize(D3D12_DESCRIPTOR_HEAP_TYPE_RTV);
D3D12_CPU_DESCRIPTOR_HANDLE handle = desc_heap_->GetCPUDescriptorHandleForHeapStart();
for (size_t i = 0; i < back_buffers_.size(); ++ i)
{
swap_chain_->GetBuffer(static_cast(i),
IID_ID3D12Resource, reinterpret_cast<void**>(&render_targets_[i]));
d3d_12_device->CreateRenderTargetView(render_targets_[i], nullptr, handle);
D3D11_RESOURCE_FLAGS flags11 = { D3D11_BIND_RENDER_TARGET };
d3d_11on12_device->CreateWrappedResource(render_targets_[i], &flags11,
D3D12_RESOURCE_STATE_RENDER_TARGET, D3D12_RESOURCE_STATE_PRESENT,
IID_ID3D11Texture2D, reinterpret_cast<void**>(&back_buffers_[i]));
handle.ptr += rtv_desc_size_;
}
其中NUM_BACK_BUFFERS等于2。这里比较神奇的地方是CreateWrappedResource。它的作用是把一个D3D12的资源包装成一个D3D11资源,就好像把对设备的包装一样。这么一来,同一个资源既可以在11中访问,也可以在12中访问。
这样是不是就可以了呢?运行看看吧。没有debug错误信息,没有crash,但是黑屏。就好像啥事情都没做一样。
Run,Flush,run
D3D12是要求显式地提交一个command list,才会进行渲染。在目前的渲染流程中,D3D11设备自画自的,从来没用提交。这应该就是黑屏的原因。要修好也很容易,只要在Present之前调用一下
d3d_imm_ctx->Flush();
11on12层就会把11的context中的指令提交给command queue。但即便如此,仍然是个黑屏。
Fence
长期以来,Present都是负责启动命令列表的提交。如果打开了垂直同步,Present还会阻塞程序,直到垂直同步完成。无论如何,Present涉及到了一次同步,直接测量时间就会发现这个函数很慢。虽然其实不是它慢,而是同步慢。从DXGI 1.3开始,Present就多了一种异步的模式。在这种模式下,Present一定是立即返回,开发者可以把一个event传给DXGI,在需要的时候调用WaitForSingleObject等待这个event。这等于把阻塞的Present拆开,让开发者自由调用。在event到来之前,还可以做一些逻辑层的update和UI处理,降低延迟。D3D12把这个机制变成了默认的。同时要是用一个ID3D12Fence进一步降低同步检测的开销。
在建立完swap chain之后,还需要建立一个fence和一个event。
ID3D12Fence* fence;
d3d_12_device->CreateFence(0, D3D12_FENCE_FLAG_NONE,
IID_ID3D12Fence, reinterpret_cast<void**>(&fence));
curr_fence_ = 1;
handle_event_ = ::CreateEventEx(nullptr, FALSE, FALSE, EVENT_ALL_ACCESS);
为了简化起见,我这里先模拟老的Present行为。也就是调用完Present之后立刻强制同步。
uint64_t fence = curr_fence_;
cmd_queue->Signal(fence_, fence);
++ curr_fence_;
if (fence_->GetCompletedValue() < fence)
{
fence_->SetEventOnCompletion(fence, handle_event_);
WaitForSingleObject(handle_event_, INFINITE);
}
这对性能不利,但能在不修改渲染接口的情况下移植代码。
有了这之后,是不是就能渲染了呢?再试一次。第一帧是好的,接着仍然黑屏。至少,有点进步嘛。从一开始拷贝代码到现在,才花了36分钟。也就是说,在11on12的帮助下,36分钟之内,就能把11移植到12,并且渲染出至少一帧。
为何黑屏
写代码容易debug难。图形这种东西尤为难。目前D3D12的debugger还没法正常工作,所以要从指令序列的角度上找原因是不可能了。我花了大概2小时,从最简单的画一个三角形的D3D11程序出发,一点一点移植到12,试图通过这样的单元测试来找到原因所在。最后发现,其实之前早有伏笔。
前面提到过,在12里开发者需要对每一张back buffer建立一个render target view。但在设置RTV的时候,当前的程序只设置了第一个back buffer的RTV。所以第一帧有结果,但在swap之后,它被换到front,第二帧再次试图画上去的时候,D3D11设备报了一个removing device,并停止渲染。要解决这个问题非常容易。用一个变量记录当前back buffer的index,每次Present之后加一下。
curr_back_buffer_ = (curr_back_buffer_ + 1) % NUM_BACK_BUFFERS;
而在每帧开始渲染之前,把render_targets_[curr_back_buffer_]设置成当前就可以了。现在最简单的程序可以稳定执行。
总结
整个过程不到3小时,主要的工作在前46分钟已经完成,改动的代码也就一百行左右。至此,D3D12插件已经可以开始工作。这就是渐进式移植!有了这样的结果,我们可以一点一点渐进地把整个插件逐渐移植到D3D12,最终发挥出D3D12的威力。
 FasTC的大体框架如上图所示。下面我会解析每一个步骤。
FasTC的大体框架如上图所示。下面我会解析每一个步骤。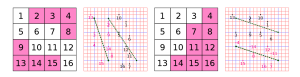 比如上图的两个block,分别可以拟合出两条直线,并直接得出它们分别是partition 31和partition 3。
比如上图的两个block,分别可以拟合出两条直线,并直接得出它们分别是partition 31和partition 3。